Optimized Design of a ZYNQ-based Hardware Accelerator for Object Detection Algorithms
Hardware accelerators for object detection algorithms are core computational modules of a system, playing a critical role in achieving efficient inference and meeting real-time processing demands. To enable efficient algorithm deployment, this chapter employs High-Level Synthesis (HLS) technology to map object detection algorithms onto hardware platforms, and integrates optimization strategies such as fixed-point quantization, operator fusion, and loop unrolling to enhance accelerator performance and algorithmic efficiency. Building upon this, a YOLOv4-tiny hardware accelerated inference module, including key operators like convolution and pooling, has been designed and implemented.
4.1 Introduction to Hardware Acceleration Tools
4.1.1 Principles of High-Level Synthesis Technology
The abstraction levels in FPGA design can be categorized into four levels from low to high: structural, RTL, behavioral, and high-level design, as shown in Figure 4-1. The lowest level, structural abstraction, directly manipulates fundamental hardware units, including low-level elements such as logic gates, LUTs, and flip-flops. In practical FPGA development, designers predominantly use RTL (Register Transfer Level) abstraction for design. RTL effectively conceals low-level hardware details, focusing on describing data transfers and logical relationships between registers. Behavioral abstraction goes a step further, emphasizing algorithmic-level description and focusing on circuit functional characteristics rather than register operation details. All these levels use HDL as the design language, and as the abstraction level increases, hardware implementation details gradually become less explicit.
This chapter will adopt a high-level design approach, directly designing the hardware accelerator using high-level languages such as C/C++, and then converting the code into an HDL description via the Vivado HLS tool [69]. In actual project development, HLS technology offers significant advantages compared to traditional FPGA development: It allows designers to focus on the algorithm itself rather than hardware details; automatic conversion from high-level languages to hardware significantly shortens the development cycle; modular design supports the creation of reusable IP cores, simplifying the design process and improving code maintainability. For embedded systems, HLS's built-in optimization features can automatically adjust code to improve performance; C-level verification and C-RTL co-simulation simplify the verification process; and simultaneously reduce design costs and risks.
4.1.2 Vivado HLS-based Design Flow
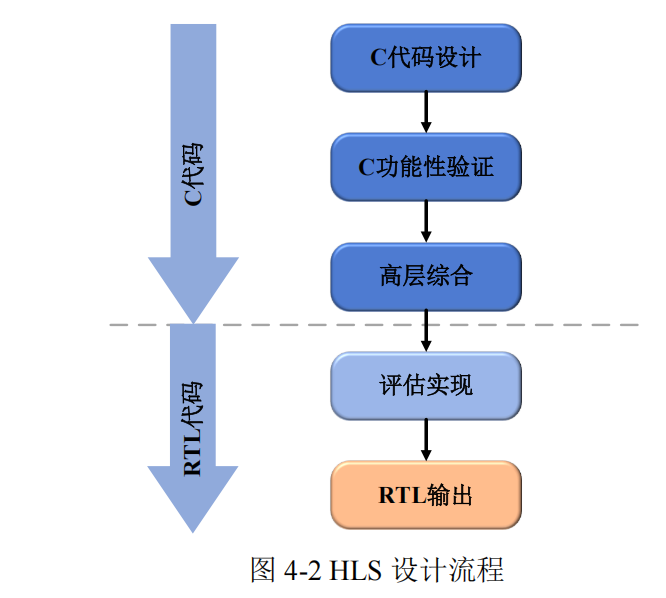
The HLS (High-Level Synthesis) flow is shown in Figure 4-2, with C/C++ design code as the primary input. Before synthesis, C simulation is first performed to verify the functional correctness of the input code. This is followed by the core step—the high-level synthesis process, which analyzes the C code and generates an RTL description based on user directives and constraints. Finally, the system outputs RTL design files in Verilog or VHDL format.
Beyond functional verification, it is equally important to evaluate the implementation effectiveness and performance metrics of the RTL design, such as whether FPGA resource utilization, latency characteristics, and maximum clock frequency meet expectations. If the requirements are not met, designers need to repeatedly adjust directives and constraint parameters and re-perform synthesis optimization to find the "optimal" solution.
4.2 Hardware Accelerator Implementation Architecture Analysis
The YOLOv4-tiny algorithm is a critical component of object detection. To achieve efficient and real-time detection tasks, selecting an appropriate convolutional neural network accelerator architecture is crucial. In the design process of convolutional neural network accelerators, the organization of data transfer and computation significantly impacts performance. Two common implementation architectures are Stream Pattern and Overlap Pattern [70].
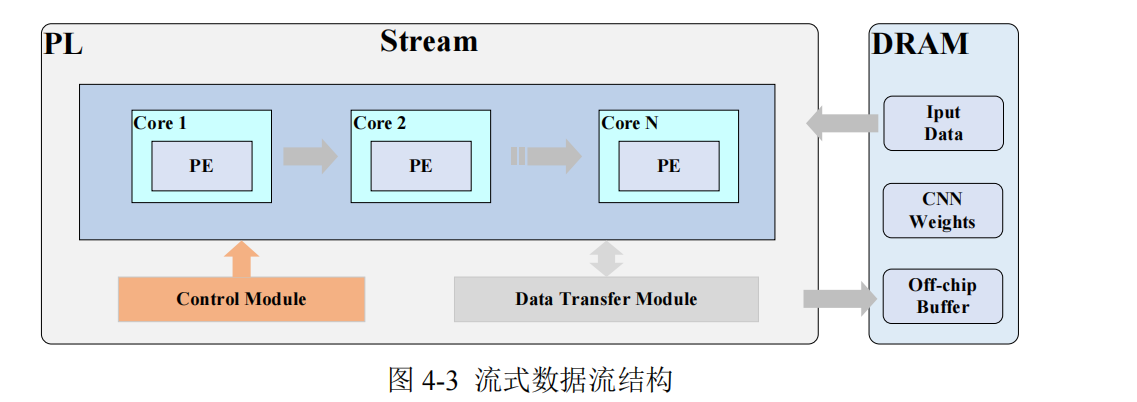
The Stream Pattern, also known as streaming data flow, is a sequential execution method, as shown in Figure 4-3. In this mode, data is read from memory and then sequentially transferred to the computation unit for processing. After the computation unit completes a calculation, the result is written back to memory. The advantage of this approach lies in its clear and straightforward data transfer and computation process. Furthermore, it can adopt diverse, targeted strategies to optimize the implementation and parallel processing schemes of each hardware kernel based on the characteristics of different computational layers, thereby effectively improving overall throughput. However, because data transfer and computation are strictly sequential, computation units may remain idle while waiting for data transfer to complete, leading to lower resource utilization and reduced flexibility.
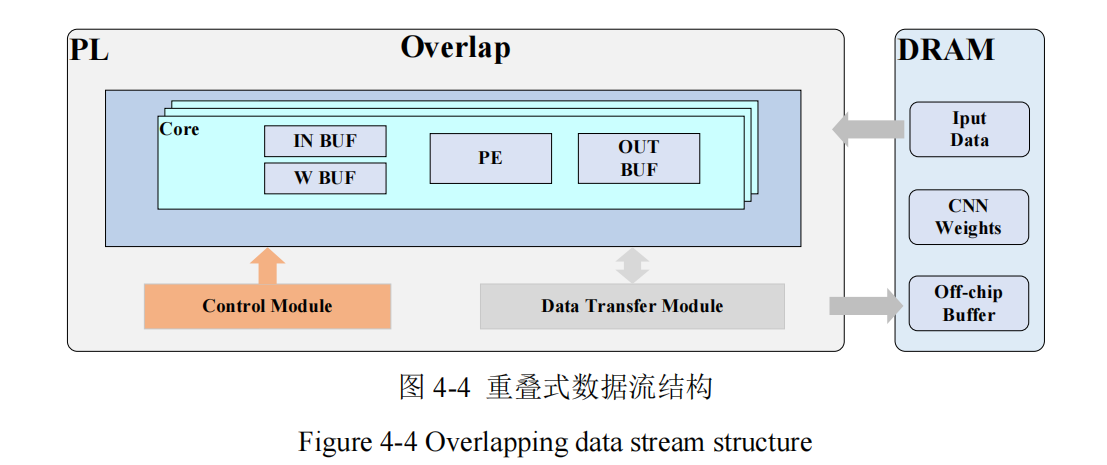
The Overlap Pattern, also known as overlapped data flow, is a method where data transfer and computation overlap, as shown in Figure 4-4 [71]. In this mode, data reading, computation, and writing back operations can partially overlap. While one portion of data is being processed in the computation unit, the next set of data can be simultaneously read from memory, and computation results can be written back to memory immediately after computation is complete. A major advantage of this design is its flexibility; when the input model changes but the computational operators remain the same, there is no need to redesign the hardware, which significantly saves time and resources. However, due to the adoption of a control architecture similar to general-purpose processors, such systems struggle to fully leverage energy efficiency advantages during operation. When deploying computational models based on this architecture, a dual challenge must be addressed: precisely calculating the physical specifications of core components and designing efficient task allocation strategies.
To fully leverage the PS-PL collaborative advantages of the Zynq heterogeneous platform and address rapidly evolving algorithmic scenarios, this design adopts a reconfigurable architecture based on overlapped data flow to implement the YOLOv4-tiny model, designing independent, reusable PE (Processing Element) units for common operators like convolution and pooling to improve hardware resource utilization and reduce computation unit idle time.
4.3 Hardware Accelerator Performance Optimization Strategies
In the design of hardware accelerators for object detection, performance optimization requires a precise trade-off between computational efficiency, resource utilization, and power consumption constraints. Traditional hardware acceleration solutions often suffer from performance degradation due to insufficient computational parallelism, data flow blockages, or storage bandwidth bottlenecks, making it difficult to meet the stringent requirements of embedded real-time object detection systems for high throughput and low latency. This section will optimize hardware accelerator performance from five aspects: computational precision compression, computation flow optimization, computational parallelization, data flow optimization, and storage architecture reconstruction [72].
Sienovo offers ZYNQ/ARM+FPGA industrial motherboards and algorithm customization services.