Design of an AI Image Acceleration Board Based on Nvidia Jetson + FPGA (ZYNQ)
Building AI inference at the edge often means combining the raw compute power of an NVIDIA Jetson SoC with the deterministic signal-processing flexibility of an FPGA — specifically Xilinx ZYNQ or Ultrascale+ devices. This post covers two concrete hardware designs that use this pairing: a MIPI/CameraLink video-capture board where ZYNQ feeds frames to a Jetson NX over PCIe, and a more elaborate smart-grid real-time co-simulation platform built around Jetson AGX Xavier and Xilinx VCU118/VCU128 FPGAs.
ZYNQ + Jetson NX: MIPI Video Acquisition Over PCIe
The first design is a 6U carrier board that pairs a Xilinx ZYNQ SoC with an NVIDIA Jetson Xavier NX module. The ZYNQ handles front-end image ingestion — either MIPI CSI-2 from machine-vision sensors or CameraLink from high-frame-rate industrial cameras — and the Jetson NX runs the AI inference pipeline for multi-target detection and tracking.
The interconnect between the two devices is PCIe. This is a deliberate architectural choice: PCIe gives deterministic, high-bandwidth DMA transfers between the ZYNQ's programmable logic and the Jetson's system memory, avoiding the latency jitter of USB or Ethernet while keeping the two processors loosely coupled enough to be developed and debugged independently.
Driver bring-up on this class of board follows a predictable sequence:
- PCIe enumeration — confirm the ZYNQ EP is visible to the Jetson RC after boot (
lspci, check BAR assignments). - BAR mapping — map the ZYNQ's BRAM or DDR window into the Jetson's address space via a custom kernel driver or a framework like XDMA.
- DMA descriptor ring — configure scatter-gather DMA so the ZYNQ can push captured frames directly into pinned Jetson memory without CPU intervention on either side.
- Frame-sync signaling — tie a GPIO or interrupt line between ZYNQ PL and Jetson so the inference pipeline can wake on frame-ready rather than polling.
Hardware schematics for this board are shown in the images above and cover the PCIe edge connector, power rails, and the ZYNQ-to-Jetson signal routing.
Target application: electronic countermeasures and UAV tracking
One documented use case for this platform is an electronic-warfare / unmanned-systems scenario: a CameraLink high-frame-rate camera feeds raw imagery into the ZYNQ, which pre-processes and buffers frames, then streams them to the Jetson Xavier NX for real-time object detection and lock-on. The same architecture generalises to radar-assisted vision controllers and any application that needs sub-millisecond frame latency from sensor to inference result.

FPGA-Jetson Real-Time Co-Simulation for Smart Grids
The second design extends the same hardware pairing to a completely different problem domain: real-time hardware-in-the-loop (HIL) co-simulation of a smart grid — a cyber-physical power system (CPPS) where a power network and a communications network are tightly coupled.
Why hardware co-simulation?
Existing software co-simulation tools (PSCAD/EMTDC, MATLAB Simulink on the power side; NS2/NS3, OMNeT++, OPNET on the network side) synchronise their state through a software handshake at each simulation timestep. Because power simulation is time-step-driven and network simulation is event-driven, keeping them aligned requires modifying the network simulator's internal loop, which introduces synchronisation overhead that makes real-time operation impossible. Commercial hardware simulators like RT-LAB and RTDS solve this but are expensive, closed, and difficult to extend.
The proposed architecture replaces both with an open, reconfigurable FPGA-Jetson platform:
- FPGA (Xilinx VCU118 / VCU128) — handles the power-facilities layer: solving the ODEs of the equivalent RLC circuit network at each simulation timestep.
- NVIDIA Jetson AGX Xavier — handles the ICT layer and grid-control layer, running a real-time OS (RTOS) for precise timing, and using its 8-core ARM v8.2 CPU (up to 2.2 GHz, with NEON SIMD) plus 384 CUDA cores for parallel packet-processing tasks.
- PCIe — the high-speed data channel between the two, used to exchange power-layer sampled data and control commands in real time.
Three-layer smart grid model
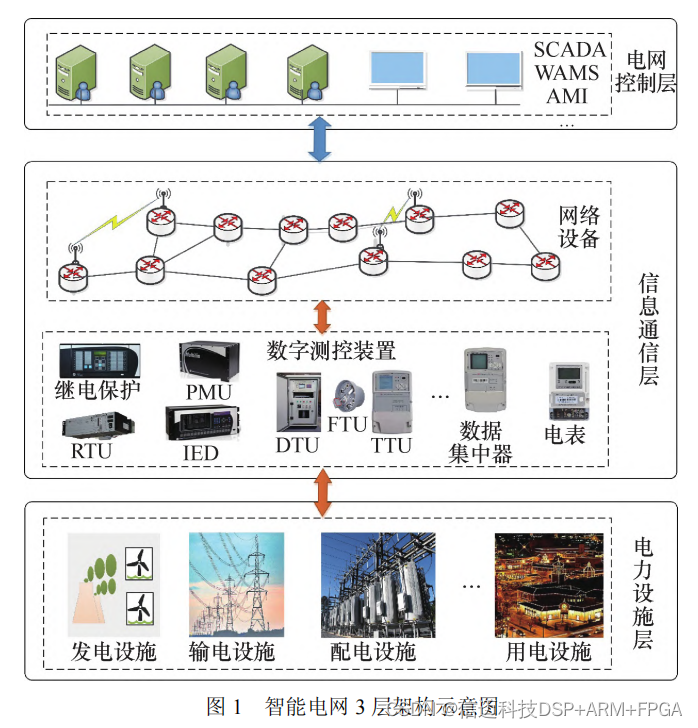
The simulation models a standard three-layer CPPS:
| Layer | Content | Simulated on |
|---|---|---|
| Power-facilities layer | Generators, transmission lines, distribution gear, storage, protection switches | FPGA |
| ICT layer | PMUs, RTUs, routers, switches, fiber links | Jetson (PTA method) |
| Grid-control layer | SCADA, WAMS, AMI control servers | Jetson |
Power-facilities layer: 20 µs EMT simulation on FPGA
The FPGA solves the power-system equations at a 20 µs timestep — a deliberate choice driven by the IEC 61850 sampling requirement of up to 256 samples per voltage cycle. At 60 Hz that works out to a 65 µs sampling interval; a 20 µs step comfortably meets it and achieves electromagnetic-transient (EMT) simulation fidelity. The VCU118/VCU128 devices were chosen for their dense LUT and BRAM resources (supporting large network topologies) and their GTH/GTY high-speed transceivers (used for multi-board scale-out when the simulated grid grows too large for a single FPGA).
Sampled power-layer results are stored in BRAM on the FPGA. The Jetson reads them via PCIe DMA calls, which feed the measurement-data generation module that packages raw electrical parameters (voltage, current, phasor amplitude and angle) into protocol-specific frames — for example, IEEE C37.118 synchrophasor packets in a WAMS scenario.
ICT layer: Parameter Timing Abstraction (PTA)
Simulating a realistic communications network in real time without hundreds of physical nodes is the harder problem. The solution introduced here is Parameter Timing Abstraction (PTA): rather than forwarding actual packets through a simulated network hop-by-hop, the transmission process is abstracted into a time-stamped parameter library of end-to-end transport parameters (latency, packet-loss rate) that were pre-computed by an offline network simulator.
At simulation runtime, whenever a measurement packet needs to travel from node A to node B, the Jetson looks up the entry in the parameter-time library at the current simulation timestamp and applies the corresponding delay and/or drop — without simulating the intermediate routing at all. Because the Jetson RTOS provides high-resolution timers, this artificial delay injection is accurate enough to produce the same observable effect on the power layer as a real network would. The key insight that makes this valid is that smart-grid core behaviour lives in the power-facilities layer; the ICT and control layers matter only insofar as they affect power-layer parameters (control-command latency, missed samples, etc.), and those effects are fully captured by the pre-computed transport-parameter curves.
This differs from earlier PTA approaches that used static, fixed-value latencies. Here the latency from A to B is a time-varying curve, capturing dynamic network conditions across the full simulation window.
For multi-region scenarios, different Jetson units handle different grid regions internally via PTA, while inter-region traffic flows over the Jetsons' physical Ethernet ports — a hybrid approach the authors call parameter-timing abstraction + physical-port mixed simulation.
Validation scenarios
The architecture was validated against two representative smart-grid topologies:
- AC-DC hybrid transmission network — a wide-area mixed transmission scenario.
- 15-node microgrid — with realistic power-device models and IEC communication protocols.
Both scenarios confirmed that the FPGA handles the 20 µs EMT timestep without overrun, the PCIe link sustains the required BRAM read bandwidth, and the Jetson RTOS delivers the timing accuracy needed for PTA packet injection.
Key Takeaways for Engineers
- ZYNQ + Jetson + PCIe is a proven physical architecture for combining FPGA sensor front-ends with GPU-accelerated AI inference. Bring-up effort is dominated by the PCIe driver (BAR mapping, DMA rings, interrupt routing).
- CameraLink → ZYNQ → PCIe → Jetson is a direct path for high-frame-rate industrial imaging pipelines where USB or GigE would be a bottleneck.
- FPGA is the right tool for hard-real-time simulation at sub-100 µs timesteps; Jetson is the right tool for anything requiring a full TCP/IP stack, a POSIX RTOS, or CUDA-accelerated parallel compute.
- PTA with a timestamped parameter library is a practical way to include network-layer effects in a real-time HIL simulation without physically instantiating every network node — as long as the simulation's ground truth lives in the layer being solved in hardware (the power layer in this case).