AM5728 High-Performance Computing (Parallel Computing) OpenCL/OpenMP Introduction and Testing
I. OpenCL/OpenMP Introduction
OpenCL (Open Computing Language) is a framework for writing programs for heterogeneous platforms. It is an API, similar to the OpenGL architecture, and this heterogeneous platform can consist of CPUs, GPUs, or other types of processors.
Recently, I spent some time briefly reviewing technologies related to high-performance computing, such as OpenMP, OpenCL, and MPI (with various implementations like Open MPI). I'm documenting a few things I learned from this quick overview here. These summaries and notes are somewhat superficial and require deeper learning and research.
First, GPU computing is becoming increasingly popular, and with China's Tianjin supercomputer claiming the top spot in international computing power, it demands attention. Existing technologies, categorized by vendor, include NVIDIA's CUDA and AMD(ATI)'s Stream. There is also an open standard: OpenCL. I am quite optimistic about OpenCL because it supports simultaneous optimization and acceleration for different brands, different core CPUs, and GPUs, making it particularly suitable for heterogeneous environments. Its basic principle is that the system has a built-in compiler-like component, similar to LLVM or an API. The code written in software is only finally compiled when it is executed on the hardware. This compilation process seems to occur through the hardware drivers within the system, which currently still require separate installation. SDKs provided by Intel, NVIDIA, and AMD each include their own drivers for execution. Therefore, the main thread of an OpenCL program determines which driver to pass the generated worker thread code to for compilation and execution, based on the number of cores in the multi-core CPU, the CPU architecture (ARM or x86), and the presence and type of GPU in the system. The system automatically saves the compiled binary code for future use. This process appears to be similar to a dynamic language, but in reality, OpenCL is still primarily written in a low-level, extended C language. The drivers for different hardware act as the runtime.
Multiple hardware manufacturers like Intel, NVIDIA, and AMD support OpenCL, but they also have their own proprietary interests. For example, NVIDIA's CUDA offers more features specific to its hardware, and its functions are reportedly more advanced. Therefore, if development is specifically for a particular hardware environment, such as developing scientific programs with large computational loads, it is best to use the GPU acceleration SDK provided by that specific hardware. OpenCL development is only preferred when generality is required, such as in commercial software.
Second, OpenMP and MPI are both widely used parallel programming libraries. Their difference is: OpenMP is for multi-core processors and uses a shared-memory parallel approach, which can be described as more thread-oriented; MPI is for scenarios involving multiple symmetric parallel CPUs or clustered servers, where the memory sharing method is mixed, making it more process-oriented.
From a certain perspective, OpenCL has the potential and trend to replace OpenMP, as it will include handling for multi-core CPUs. However, in the current environment, OpenMP is still more suitable—it can directly leverage the capabilities of multi-core processors without requiring knowledge of graphics development. Here is an article on OpenMP and OpenCL performance testing.
Current parallel development primarily involves MPI + OpenMP. The former is responsible for distributing computations across different CPUs on different servers via processes, while the latter is responsible for effectively utilizing the performance of each core within a CPU through multi-threading.
Third, some articles indicate that to maximize thread efficiency, under the same algorithmic conditions, it is best for the number of threads used by the program to match the maximum number of threads provided by the CPU, and it is best to bind program execution threads to CPU cores. GPUs are particularly effective at accelerating certain computations and offer good efficiency, but since they must be scheduled by the CPU via PCI, the latency of this communication process must be considered during actual program design.
Finally, several existing parallel computing technologies include:
-
System level: Using process migration technology to enable parallelism for all multi-process-supported programs, such as openMosix, which requires a patched operating system.
-
Hardware level: GPU acceleration technologies like OpenCL, which require corresponding hardware support.
-
Development language level: Dynamic languages like Erlang now provide support for clustered environments, automatically distributing computation processes to servers joining the cluster. Google Go language might be similar.
II. AM5728 OpenCL/OpenMP Testing
2 OpenMP Example Compilation
Execute the following command in Ubuntu to install gawk, a text search and replace tool:
Host# sudo apt-get install gawk
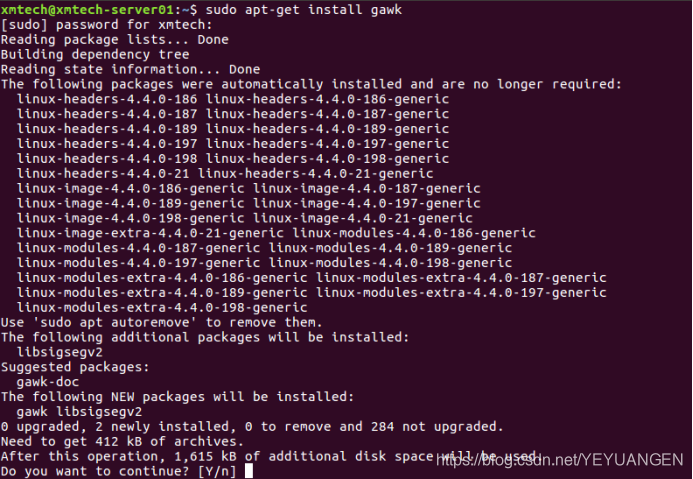
Figure 1
Enter Y to confirm installation. The successful installation is shown in the figure below:
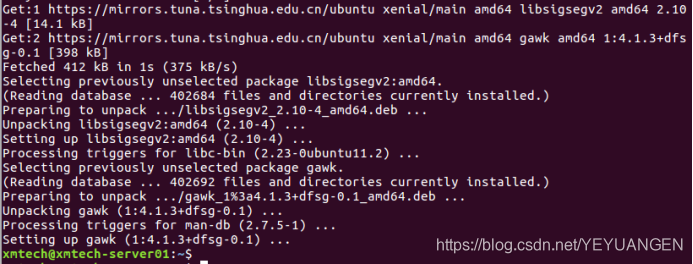
Figure 2
Confirm that the corresponding version of the Linux Processor-SDK package is correctly installed. Navigate to the SDK installation root directory and execute the following command to compile the OpenMP examples:
Host# make openmpacc-examples
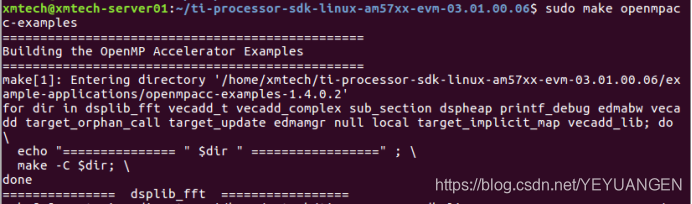
Figure 3
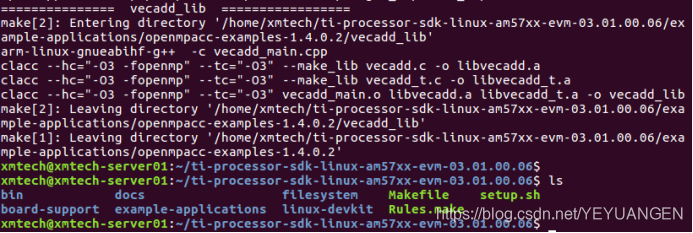
Figure 4
Copy the compiled executable files to the development board's file system. For customer testing convenience, Sienovo provides verified OpenMP executables located at "CD Demo\OpenMP\bin\openmp.tar.gz". Copy this file to the development board's file system. Navigate to the file's location in the file system and execute the following command to decompress it:
Target# tar xvf openmp.tar.gz
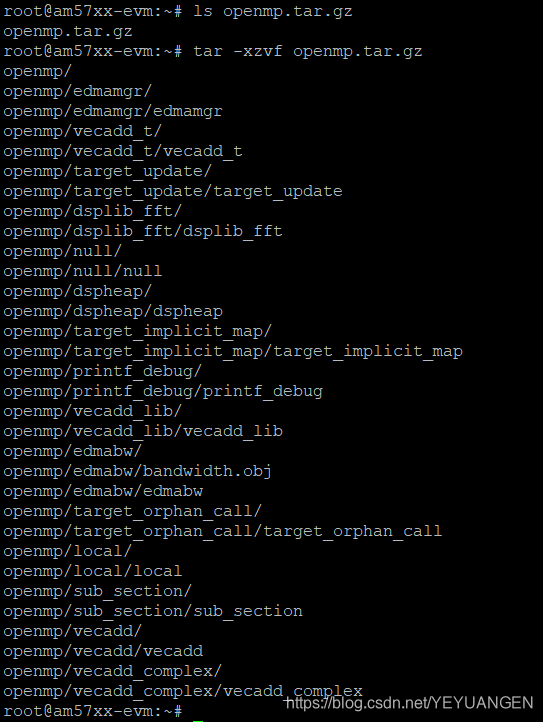
Figure 5
3 OpenMP Example Testing
3.1 dspheap Example
This example demonstrates how to create and use heaps on the DSP within an OpenMP target region. DSP built-in functions are used to create user-defined heaps that operate in MSMC, DDR, and local memory regions. These heaps are persistent as long as their underlying memory is allocated. In this example, buffers are created from contiguous shared memory regions to provide underlying memory storage. Heaps are active and persistent from their initialization until the buffers are deallocated.
Execute the following commands in the development board's file system to run this example:
Target# cd openmp/dspheap/
Target# ./dspheap
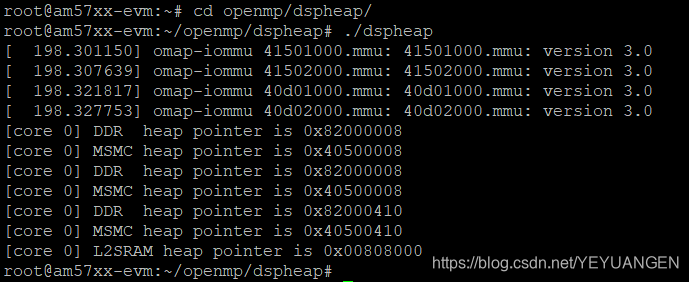
Figure 6
3.2 vecadd Vector Addition Example
This example uses OpenMP for parallel addition of two 8K-element one-dimensional vectors. Execute the following commands in the development board's file system to run this example:
Target# cd openmp/vecadd/
Target# ./vecadd
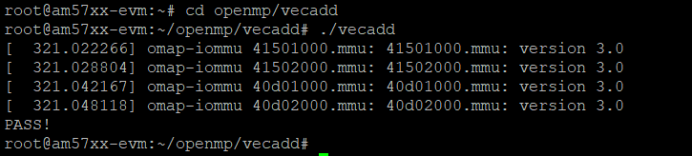
Figure 7
3.3 vecadd_complex Example
This example uses OpenMP for parallel addition of two 8K-element complex vectors. Execute the following commands in the development board's file system to run this example:
Target# cd openmp/vecadd_complex/
Target# ./vecadd_complex
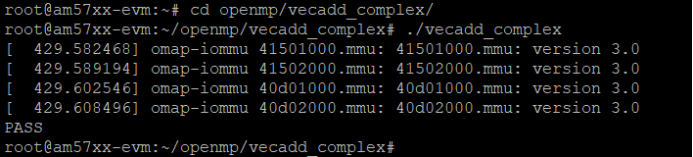
Figure 8
3.4 Other Example Testing Instructions
The testing method for other programs is the same as above. The specific program functionalities can be found in the comments of the source .C files, located in the Linux Processor-SDK installation package root directory at "/example-applications/openmpacc-examples-1.4.0.2/".