Design of a Convolutional Neural Network Accelerator Based on ZYNQ FPGA+AI+ARM
Research on FPGA-based Convolutional Neural Network Accelerators
With the rapid development of deep learning, Convolutional Neural Networks (CNNs) have achieved remarkable results in tasks such as image classification and object detection. However, traditional hardware implementations of CNNs face issues such as insufficient computational power, high energy consumption, and large latency. Field-Programmable Gate Arrays (FPGAs) possess high programmability and parallel processing capabilities, allowing for optimized hardware architectures for specific applications, which can significantly improve CNN inference speed and energy efficiency. Existing FPGA accelerators suffer from problems such as low resource utilization, high design complexity, and data transfer latency bottlenecks, which limit the further practical application of CNNs. Therefore, this paper conducts research from the perspectives of CNN architecture and IP design, aiming to design a high-efficiency, low-power, and practical FPGA-based Convolutional Neural Network accelerator.
FPGA Convolutional Neural Network Accelerator Architecture Design
This chapter will focus on the design of FPGA-based Convolutional Neural Network accelerator architecture. First, an analysis of the hardware implementation of the CNN to be deployed on hardware will be conducted, including an analysis of network computation and parameter counts, as well as memory access and computation parallelism. Second, to better deploy CNNs on hardware, a double buffering mechanism is adopted to improve design throughput, convolutional layers are fused with BN layers, and network parameters are subjected to fixed-point quantization. Finally, a convolutional accelerator based on the Overlap architecture is designed.
3.1 Hardware Implementation Analysis
3.1.1 Network Computation and Parameter Analysis
Before hardware implementation, it is necessary to analyze the computation and parameter counts of the CNN to determine the specific hardware accelerator architecture and target board. When performing network hardware implementation analysis, attention should be paid to the total number of parameters and total computation of the model. This paper uses Python's torchstat and ptflops tools to count the total computation and total parameters of the model. Figure 3.1 shows the total parameters and total computation of the CNN, where the total parameters are 5.92M and the total computation is 3.43 GFlops.
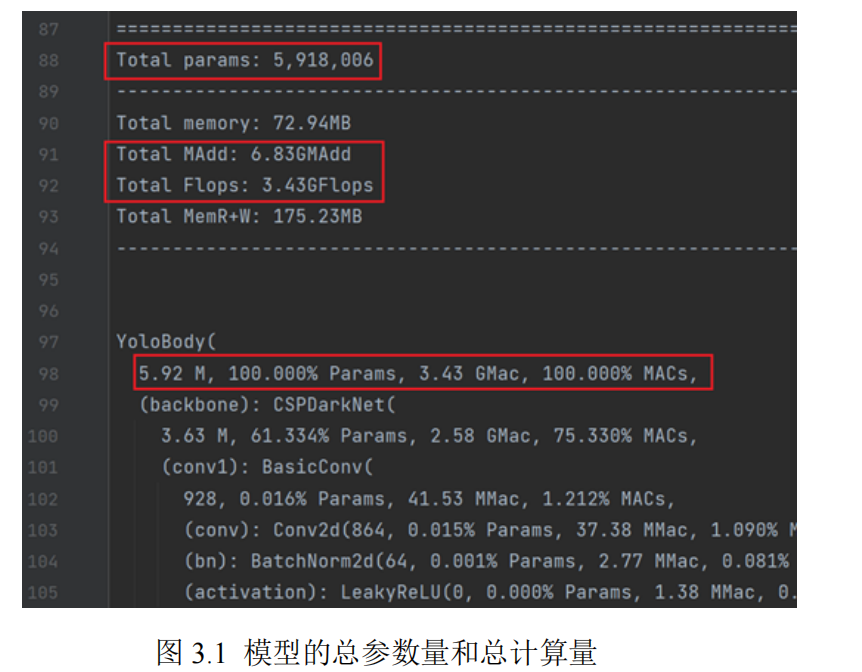
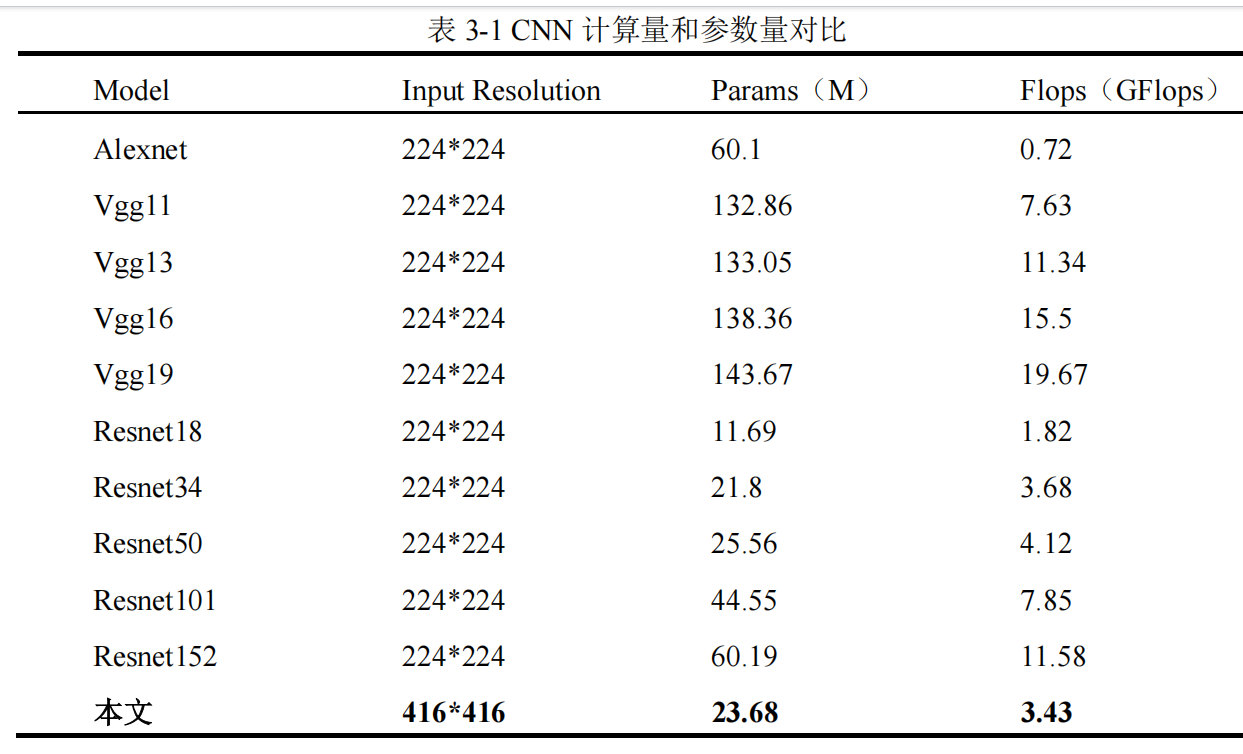
Table 3-1 shows a comparison of the total computation and total parameters of the lightweight CNN selected in this paper with other CNNs. The total parameters and total computation of the CNN selected in this paper are relatively small compared to other CNNs, which is more conducive to deployment on embedded devices.
When performing hardware implementation, to better adapt to limited resource environments and improve the operational efficiency of CNNs, the following two issues need to be considered:
(1) Whether parameters are stored in on-chip memory or off-chip memory.
Although storing parameters in on-chip memory allows for faster read speeds and more efficient computation, the capacity of on-chip memory is limited. When the network parameter size exceeds the storage limit of on-chip memory, parameters can only be stored in off-chip memory. This paper selects DDR as the off-chip memory, allowing for a theoretical storage capacity of parameters up to the GB level.
(2) How to improve the accelerator's throughput for faster inference speed.
To achieve higher inference speeds for trained models on FPGAs, it is necessary to improve the design's throughput. This typically involves specific optimizations for computationally intensive operators, such as increasing parallelism and pipelining.
As can be seen from the CNN network structure in Section 2.2, the convolutional model used in this paper has a total of 8 types of operators, including Conv2D with 3 configurations, LeakyReLU, Concat, Maxpool2d, Upsample, and BN. Among these, the BN layer will be fused with the convolutional layer, eliminating the need for a separate operator IP design during hardware implementation. Furthermore, the only operators with trainable parameters are Conv2D and BN; the remaining operators perform fixed computations and do not have trainable parameters.
Since LeakyReLU, Maxpool2d, and Upsample are layers with only computation and no parameters. Concat is a call to a PyTorch API, equivalent to an already defined function, so Concat is not included in the statistics. In commonly used network layers, fully connected layers have a large number of trainable parameters, so the focus of CNN accelerators is to accelerate convolutional layers and fully connected layers.
3.1.2 Memory Access Parallelism Analysis
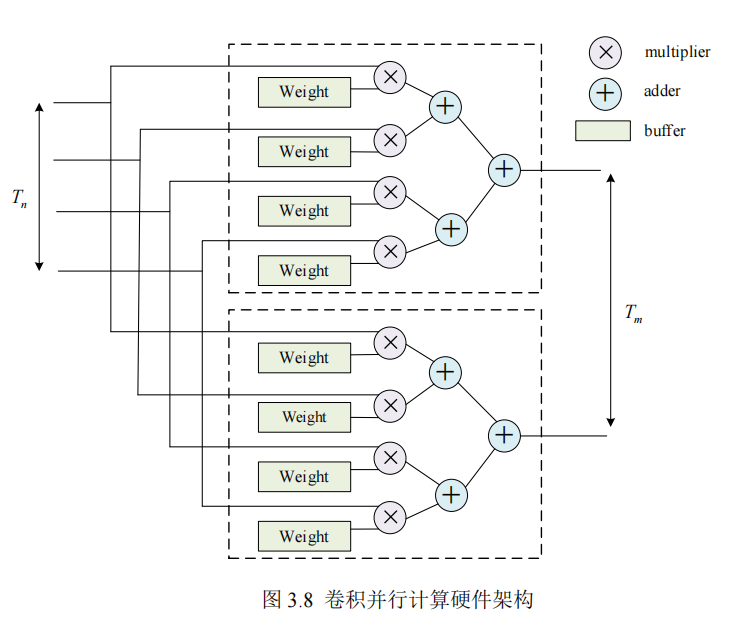
Due to the relatively limited on-chip memory resources of FPGAs, and the fact that convolutional neural network weights and feature maps of intermediate computation results typically occupy large storage space, it is impractical to cache entire feature maps in on-chip BRAM. Therefore, a loop tiling strategy is adopted to divide data in large loops into smaller blocks, to enhance data locality, thereby improving cache utilization and reducing memory access latency.
3.3 Accelerator Architecture Design
Figure 3.13 shows the architecture diagram of a convolutional accelerator based on the Overlap architecture designed in this paper. Compared to the traditional Von Neumann architecture, the Overlap architecture can effectively alleviate the bottleneck problem caused by data movement. In traditional architectures, data is frequently transferred between memory and processor, resulting in significant time overhead