ZYNQ-based ARM+FPGA+YOLO AI Real-time Fire Monitoring and Recognition System
2.1 Overall System Design Flow
This paper studies a monitoring system, which requires image acquisition. The system should be able to connect to cameras or other image sensors to acquire image data in real time. Next, logical design is performed on the FPGA to achieve real-time image preprocessing [27-28], including denoising, Gaussian filtering, and histogram equalization, to improve the accuracy of subsequent processing. To meet the system's scalability requirements, a Linux operating system [29-30] is ported to the ARM, and an Ethernet connection is configured to facilitate peripheral expansion. To achieve hardware acceleration, Xilinx's DPU module is called to improve the efficiency and performance of image processing. Furthermore, the system should possess long-term stability. Figure 2.1 shows the schematic diagram of the overall solution.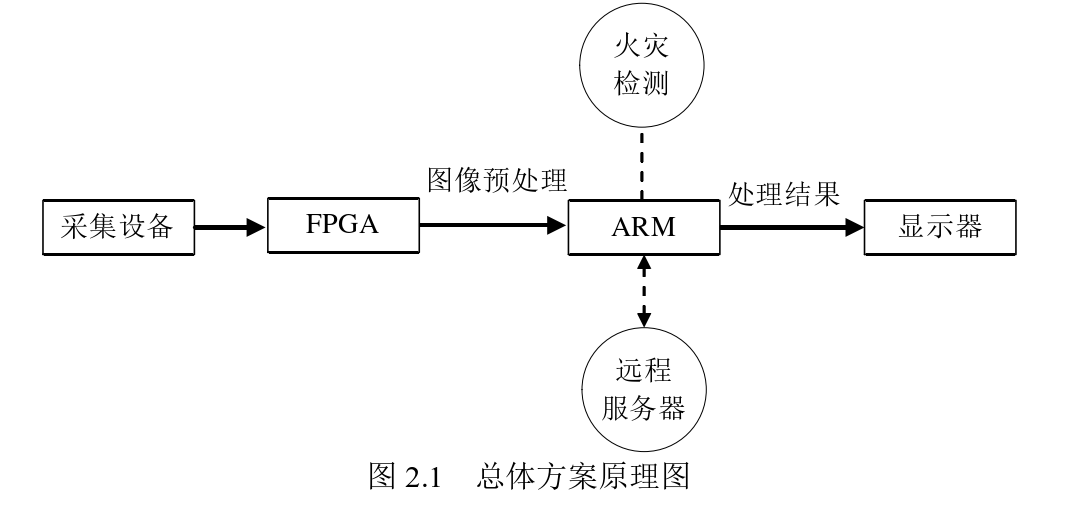 2.2 Monitoring System Hardware Design
The hardware design of this system includes circuit design, FPGA logic design, and PS (Processing System) configuration. The PS side connects to an SD card, UART interface, DP interface, and Ethernet interface, and custom IP cores are designed in the PL (Programmable Logic) through logic design. Figure 2.2 shows the Zynq hardware architecture diagram.
2.2 Monitoring System Hardware Design
The hardware design of this system includes circuit design, FPGA logic design, and PS (Processing System) configuration. The PS side connects to an SD card, UART interface, DP interface, and Ethernet interface, and custom IP cores are designed in the PL (Programmable Logic) through logic design. Figure 2.2 shows the Zynq hardware architecture diagram.
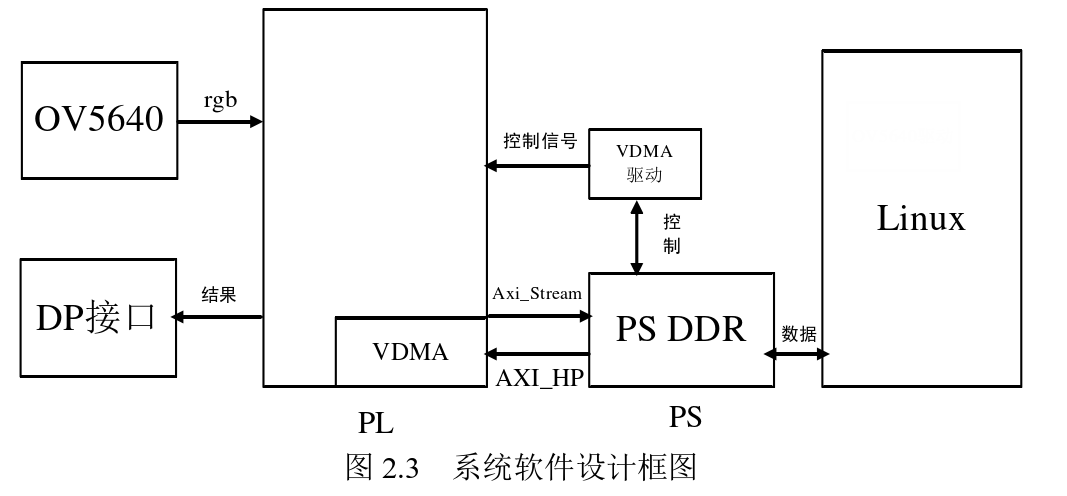
 2.3 Monitoring System Software Design
In the software design, Linux needs to be ported to the ARM side, and drivers for the camera and VDMA need to be written.
2.3 Monitoring System Software Design
In the software design, Linux needs to be ported to the ARM side, and drivers for the camera and VDMA need to be written.
 2.4 ZYNQ Platform Introduction
2.4.1 ZYNQ Development Flow
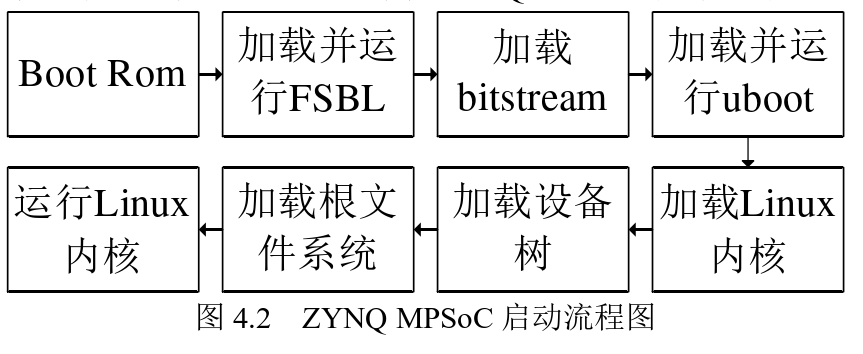
The ZYNQ System-on-Chip (SoC) development process integrates the concept of software and hardware co-design to achieve efficient system performance and functional optimization. Development is carried out using the Xilinx suite, specifically including Vivado and Vitis software. Figure 2.4 visually illustrates the Xilinx development tool flow.
2.4 ZYNQ Platform Introduction
2.4.1 ZYNQ Development Flow
The ZYNQ System-on-Chip (SoC) development process integrates the concept of software and hardware co-design to achieve efficient system performance and functional optimization. Development is carried out using the Xilinx suite, specifically including Vivado and Vitis software. Figure 2.4 visually illustrates the Xilinx development tool flow.


5.3.2 Network Model Training
Generally, the accuracy of models increases with the number of training iterations. However, accuracy often fluctuates significantly across many training iterations. This design employs semi-supervised learning simulation to enhance recognition performance. The best model generated from the first 50 epochs is saved and used as the initialization model for the second round, which leads to relatively stable accuracy. Figure 5.10 shows the loss rate and accuracy curves for three different models. 5.3.2 Network Model Training
Generally, the accuracy of models increases with the number of training iterations. However, accuracy often fluctuates significantly across many training iterations. This design employs semi-supervised learning simulation to enhance recognition performance. The best model generated from the first 50 epochs is saved and used as the initialization model for the second round, which leads to relatively stable accuracy. Figure 5.10 shows the loss rate and accuracy curves for three different models.
5.3.2 Network Model Training
Generally, the accuracy of models increases with the number of training iterations. However, accuracy often fluctuates significantly across many training iterations. This design employs semi-supervised learning simulation to enhance recognition performance. The best model generated from the first 50 epochs is saved and used as the initialization model for the second round, which leads to relatively stable accuracy. Figure 5.10 shows the loss rate and accuracy curves for three different models.
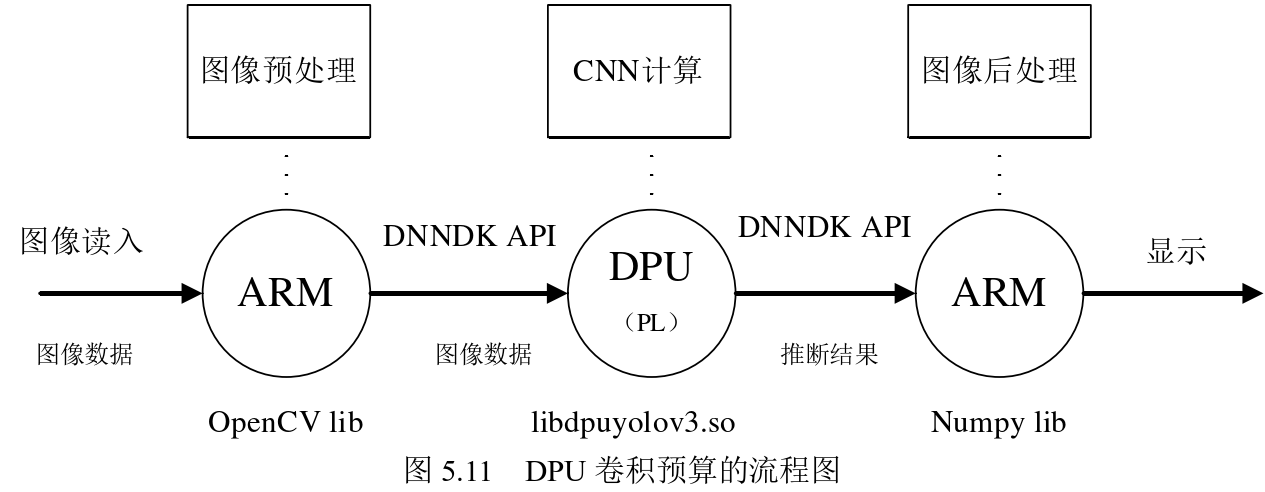
.3.3 DPU Acceleration
Xilinx's dedicated neural network unit, the DPU module [60-62], can perform computations efficiently, especially in convolution modules, providing higher speeds for neural network modules. In practical operation, the DPU IP is called on the Linux system of the PS side to perform neural network computations. Figure 5.11 shows the flowchart for DPU convolutional computation.