C Perspective (Part 1) - Any C Program Can Be Understood as a Pointer Pointing to a Character, Followed by Character Matching
C Perspective - Understanding Character Matching in C Programs
In this article, we will explore the concept of character matching within C programs, focusing on the simple matching algorithm and the more advanced Knuth-Morris-Pratt (KMP) algorithm. Understanding these algorithms is crucial for anyone involved in string processing or searching tasks in programming.
1. History of Character Matching
Character matching has a rich history in computer science, particularly in the context of string searching. The need for efficient algorithms to find substrings within larger strings has led to the development of various algorithms, each with its own advantages and trade-offs.
2. Character Matching Algorithms
I. Simple Matching Algorithm
Let's start with a straightforward example to illustrate the simple matching algorithm. Suppose we want to search for the substring T = "abcabd" within the string S = "abcabcabdabba". We can assume a 0-based indexing system for our characters.
-
Comparison Process: We begin by comparing the characters of S and T sequentially:
- Compare S[0] with T[0]
- Compare S[1] with T[1]
- Continue this process until we reach S[5] and T[5], where we find a mismatch.
The comparison process can be visualized as follows:
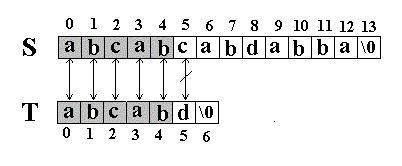
-
Handling Mismatches: When a mismatch occurs, the algorithm requires backtracking:
- The index for T resets to the beginning (T[0]).
- The index for S backtracks to the start of the current comparison and then increments by 1.
- The comparison restarts from the new positions.
This process continues until either a match is found or all possibilities are exhausted.
-
Worst-Case Scenario: The worst-case time complexity for the simple matching algorithm occurs when the source string S has m characters and the target string T has n characters. In this case, the maximum number of comparisons can reach (m-n)*n. This situation typically arises when the algorithm matches all characters up to the end of S without finding a complete match for T.
3. KMP Algorithm
To improve upon the simple matching algorithm's inefficiencies, we turn to the Knuth-Morris-Pratt (KMP) algorithm, which was developed by Donald Knuth, Vaughan Pratt, and James H. Morris. The KMP algorithm enhances the matching process by utilizing information gathered during the matching process to avoid unnecessary comparisons.
The KMP algorithm preprocesses the pattern T to create a "partial match" table (also known as the "prefix" table) that indicates how far to backtrack in T when a mismatch occurs. This allows the algorithm to skip over sections of S that have already been matched, significantly reducing the number of comparisons needed.
4. Applications and Interview Question Analysis
Understanding character matching algorithms is not only essential for software development but also a common topic in technical interviews. Questions regarding string searching can often lead to discussions about the simple matching algorithm versus the KMP algorithm, as well as their respective time complexities and use cases.
In summary, character matching is a fundamental concept in programming, particularly in C, where pointers and memory management play a crucial role. By grasping these algorithms, developers can write more efficient code for string searching and manipulation tasks.