Demystifying Binary Trees (Part One)
This article aims to provide an accessible explanation for common confusions encountered during personal study of binary trees. Donald Knuth has a book, 'The Art of Computer Programming,' which discusses how 0s and 1s construct the vast world. Binary trees are an introductory topic in the non-linear part of data structures, and one of the most fascinating and widely used structural forms in the computer world (e.g., file directories are tree structures). Starting from the simplest definitions and deriving the various properties of binary trees, as well as operations like traversal, insertion, deletion, and sorting, is highly valuable for logical training and learning about computers themselves.
I. Binary Tree Storage
Sequential Storage: Full binary trees;
Linked Storage: Saves space;
II. How to Understand Binary Tree Recursive Traversal? (Code) [Refer to the Recursion and Stack chapter]
Once binary tree storage (primarily linked storage) is understood, the first challenge in binary tree basics is how to traverse them. The principle of binary tree traversal is from top to bottom, and from left to right. Based on the order of visiting the root node, there are three main traversal methods: pre-order traversal (root-first), in-order traversal (root-middle), and post-order traversal (root-last).
The definition of a binary tree is recursive: it consists of a root node, followed by a left subtree and a right subtree. The left subtree can then be viewed as another tree, which in turn has its own root node, left subtree, and right subtree. This recursive definition continues until a leaf node is reached (a leaf node is also a form of tree, but its left and right subtrees are empty). Thus, recursion has a termination condition, allowing for layer-by-layer returns.
Below, a simple binary tree is used to illustrate pre-order traversal with a diagram.
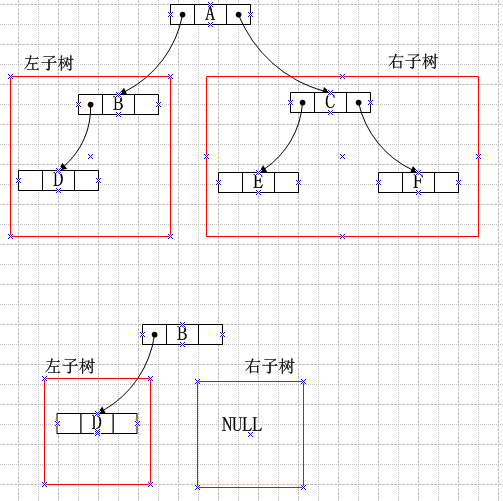
How binary tree recursion works
III.