RK3399pro + K7/A7 FPGA + AI Domestic Artificial Intelligence Image Processing Platform
The RK3399Pro is a Rockchip SoC that shipped with an integrated Neural Processing Unit (NPU) at a time when on-device AI inference for embedded Linux was still a niche capability. This post covers a hands-on benchmark of the RK3399Pro NPU using Rockchip's own toolkit, compares it to the Jetson Nano, and notes the real-world caveats you'll run into when porting existing detection networks to the platform.
What Is the RK3399Pro?
The RK3399Pro is built on the same dual Cortex-A72 + quad Cortex-A53 big.LITTLE cluster as the standard RK3399, but adds a dedicated NPU die. Rockchip initially quoted the NPU at 2.4 TOPS in pre-release materials. Post-launch measurements by the community put the actual sustained throughput closer to 3.0 TOPS — a meaningful over-delivery that made the chip significantly more competitive than early datasheets suggested.
For context, the NVIDIA Jetson Nano delivers 0.47 TFLOPS of FP16 compute via its 128-core Maxwell GPU. The two figures use different units (TOPS = tera-operations per second over INT8; TFLOPS = tera floating-point operations per second), so direct numeric comparison is misleading. The only fair method is to run the same neural network on both platforms under the same conditions and compare frames per second — which is exactly what this evaluation does.

Test Setup
The benchmark was run on the following hardware and software stack:
| Item | Detail |
|---|---|
| Board | TB-RK3399Pro |
| RAM | 3 GB |
| Flash | 16 GB |
| Toolkit | Rockchip RKNN Toolkit v1.0.0 |
The RKNN Toolkit is Rockchip's model conversion and inference pipeline. It takes models trained in common frameworks (TensorFlow, Caffe, PyTorch via ONNX, etc.), quantizes them to INT8, and compiles them into the .rknn binary format that the on-chip NPU can execute directly. Version 1.0.0 was the first stable public release, meaning operator coverage was still growing at the time of this test.
Benchmark Results
The results image below shows inference throughput (frames per second) across a set of standard vision networks:
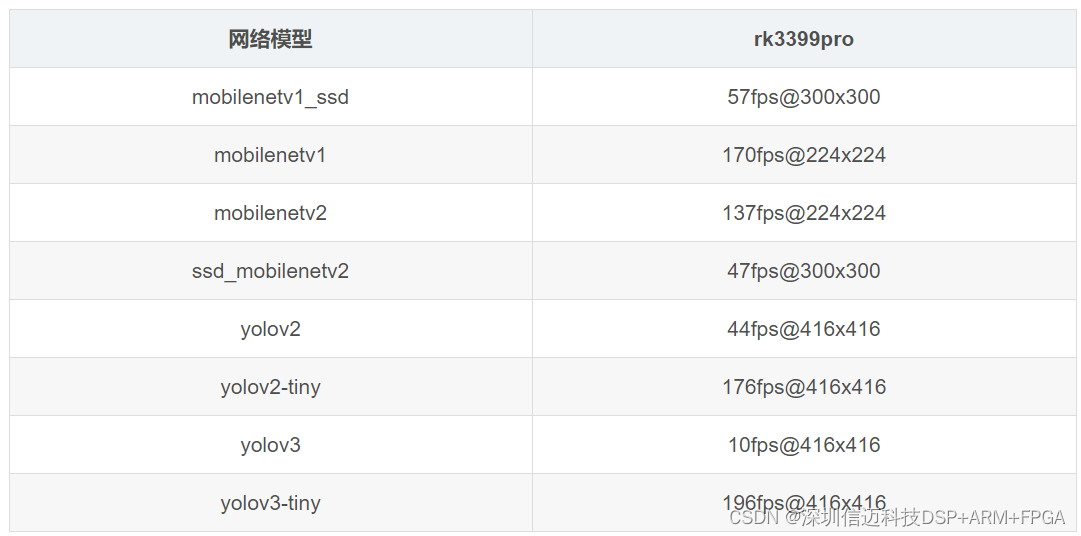
YOLOv3 Anomaly
The most notable finding is that YOLOv3 posted only ~10 fps on toolkit 1.0.0, whereas forum reports using the earlier toolkit 0.9 consistently achieved around 30 fps. The most plausible explanation is that the official test used a modified YOLOv3 topology — for example, a stripped-down input resolution or a reduced number of detection scales — rather than the full 608×608 or 416×416 standard network. Because Rockchip did not publish the exact network graph used in their reference numbers, it is difficult to reproduce the 30 fps figure on a stock YOLOv3 without digging into the forum's toolkit 0.9 model files. If YOLOv3 throughput is critical to your project, it is worth testing both toolkit versions and confirming which network variant each uses.
Overall Assessment
Despite the YOLOv3 surprise, the broader picture is positive. For mainstream networks — lightweight classifiers, MobileNet-based detectors, and similar architectures with standard layer types — the RK3399Pro NPU delivers throughput that is well above pre-release expectations and competitive with much pricier edge-AI hardware at the time.
The practical implications:
- Drop-in usability for standard topologies. If your network uses conv, depthwise conv, BN, ReLU, pooling, and standard fully-connected layers, the RKNN Toolkit 1.0.0 conversion pipeline handles them without manual intervention. You can port a trained model to the NPU in a single afternoon.
- Custom layers are the bottleneck. The toolkit's operator coverage at v1.0.0 is not exhaustive. Any layer type that falls outside the supported set will cause the conversion to fail or fall back to CPU execution, negating the NPU speedup. The workaround at the time was to split the graph: run unsupported layers on the A72 cores and delegate the supported subgraph to the NPU. This is cumbersome but feasible for research prototypes.
- Wait for toolkit updates for exotic architectures. Transformer-based vision models, non-standard attention mechanisms, and other cutting-edge topologies were not realistically portable at v1.0.0. Newer RKNN Toolkit releases have progressively expanded the operator set, so revisiting a failed conversion after a toolkit upgrade is often worthwhile.
Integration Context: K7/A7 FPGA + RK3399Pro Platform
The platform described in the article title pairs the RK3399Pro SoC with a Xilinx K7 (Kintex-7) or A7 (Artix-7) FPGA. This is a common architecture for industrial AI imaging applications: the FPGA handles deterministic real-time pre-processing (sensor interfacing, ISP pipeline, geometric correction, high-speed DMA), while the RK3399Pro NPU runs the inference workload. The CPU cores on the RK3399Pro coordinate the pipeline and handle application logic. The result is a domestically sourced (from the perspective of the Chinese market) all-in-one compute platform for machine vision, quality inspection, and similar industrial AI tasks — without relying on NVIDIA or Intel inference hardware.

Takeaways
- The RK3399Pro NPU's real-world throughput (≈3.0 TOPS measured) exceeded its datasheet spec (2.4 TOPS), making it a strong candidate for embedded AI vision workloads.
- Direct TOPS-vs-TFLOPS comparisons with the Jetson Nano are not meaningful; network-level FPS benchmarks are the correct comparison method.
- The RKNN Toolkit v1.0.0 handles standard layer types cleanly but stumbles on custom or exotic operators — plan your network architecture accordingly or target a later toolkit version.
- The YOLOv3 regression between toolkit 0.9 and 1.0.0 is worth investigating if object detection throughput is a hard requirement; always validate against the specific toolkit version you intend to ship with.