基于 ZYNQ MPSOC 异构平台的道路交通目标检测设计,也支持RK3588+FPGA
0
引言近年来,我国的汽车产业不断升级发展
,新 能源电动汽车的销量比重不断增加
,汽车逐渐向科技化、智能化发展
。智能汽车上的自动驾驶技术以及行车的安全检测都离不开目标检测技术,传统的目标检测通过人工设计并手动提取特征,检测精度不高。随着深度学习技术以及卷积神经网络的崛起
,深度学习算法已经取代传统算法,成为当前目标检测任务的主流算法常规的深度学习算法通常部署在高性能的计算机中,计算机体积大、功耗高,不便于安装在汽车内。
将目标检测算法部署到嵌入式边缘设备上能够有效解决上述问题,边缘设备的功耗较低、体积较小可以灵活地进行安装部署
。当前的深度学习边缘部署主要使用
ASIC 平台
,但
ASIC
是一种定制化平台,通常只针对单一模型,且从设计、验证到流片阶段需要消耗大量时间和资金,设计完成后也难以进行更改,面对快速发展的神经网络模型很难保证能够及时适应。而 FPGA
凭借其硬件结构具备的可重构性和低功耗特点
,可以灵活地进行设计和修改,能够更好地适应网络模型的升级、调整、部署。
针对
FPGA
神经网络模型部署问题,陈辰等设计了基于 FPGA
的单指令流多数据流卷积神经网络加速器架构,通过高层次综合方法部署
YOLOv2
网络,对加速器的性能和资源耗费进行深入分析和建模,但高层次综合生成的代码可读性差,很难进一步优化。陈浩敏等提出了基于
YOLOv3-tiny
的 网络模型加速器,通过轻量化网络模型,满足了嵌入式领域的部署要求,然而轻量化后网络的精度较低。
武世雄等提出了一种基于参数量化的卷积神经网络加速器,该加速器对参数进行了
8 bit
定点量化和重新排序,有效减少了内存占用和访存次数,提高了带宽的利用率,同时该研究采用滑动窗口间并行策略进行加速,提高了图像分类速度。
上述几种方案都在
FPGA
上对神经网络进行部署,但是此类加速器均要求对单一网络进行硬件上的单一设计优化,灵活性较低,对于非专业硬件开发人员来说,开发难度大、周期较长,难以适应快速迭代的神经网络模型部署。因此,需要一种普适性强、能够对基本的网络模型算子支持、开发周期短、开发流程简洁的神经网络模型加速方法。
针对上述问题,本文提出了一种基于
FPGA+
ARM
异构平台的道路交通目标检测方案,通过增加网络检测层得到改进的
YOLOv3-4L
网络来提升模型检测精度,通过剪枝、量化等方式降低网络的参数和计算量得到
YOLOv3-4L-prune
网络来提升检测速度,在底层硬件端以深度处理单元(
Deep Learning
Processing Unit
,
DPU
)为核心,构建硬件平台对卷积运算进行并行加速,在部署环节通过
Xilinx
公司
Vitis AI
平台进行网络量化、编译、生成执行文件等方式对网络进行部署,实现了嵌入式平台道路交通目标检测设计。
1
目标检测算法优化
YOLOv3[
是一种广泛使用的目标检测算法,通过回归的方式检测目标物体的种类和具体的位置,其检测精度高、模型大小适中,适合部署到边缘设备上。算法原始的层特征尺度检测时部分微小汽车目标以及重叠汽车目标会被漏检,改进
YOLOv3-4L
网络结构如图所示,本文对原始算法结构进行了修改。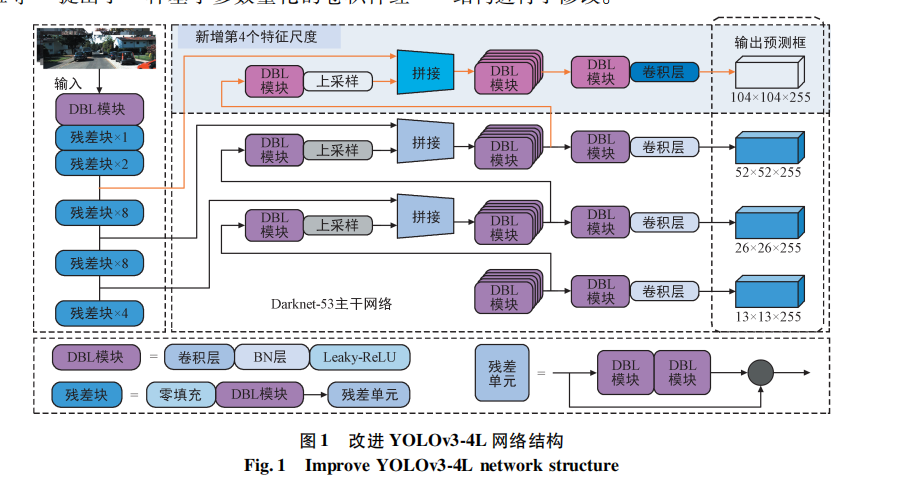
YOLOv3
的原始主干网络为
Darknet-53
,本文在算法原有 3
层特征的基础上增加了第
4 个特征尺度
(
104×104
),通过对其进行两倍上采样,将输出特征尺度从
52×52
提升至
104 ×104
。同时通过
route
层 将第
109
层与特征提取网络的第
11
层特征进行融合,以充分利用深层特征和浅层特征,更好地识别微小、重叠汽车目标。此外还进行了其他特征融合操作:对通过
2
倍上采样输出的第
85
层和第
97
层网络进行融合,通过
route
层将第
85
层与第
61
层、第
97
层与第
36
层的特征图进行融合。改进后的
4
个特征尺度分别为:
104 × 104
、
52 × 52
、
26 × 26
和
13×13
。增加模型的特征尺度能够使多尺度的信息进行融合,减轻特征丢失问题,提升语义的丰富度,增强网络的全局感官能力,改善对汽车漏检、误检的问题。
2
总体部署设计
2. 1
硬件平台设计本文硬件平台以
DPU
作为核心,与实例化的
ZYNQ Ultrascale+MPSoC IP
核、时钟模块、复位模块等各模块组合设计而成。
DPU
是
Xilinx
推出的一个可参数化的计算引擎,可以实现卷积神经网络模型、深度神经网络模型的推理功能
[
14
]
,硬件结构如图
2
所示。它相当于一组可参数化的
IP
核,部署在异构平台的
FPGA
端中,
DPU
有一个专用的指令集,该指令集支持一些常用的神经网络算子如卷积、深度卷积、最大池化和全连接等。